

[From the last episode: We looked at the common machine-vision application and its primary functions.]
We’ve seen that vision is a common AIA broad term for technology that acts more human-like than a typical machine, especially when it comes to "thinking." Machine learning is one approach to AI. function these days, and we’ve also talked about the fact that our current spate of neural networksA type of conceptual network organized in a manner inspired by our evolving understanding of how the brain works. are not neuromorphicThis refers to systems that attempt to operate in the same way that the brain operates. Spiking neural networks are the main commercial example. – that is, they’re not modeled after animal brains. But, in the case of vision, one aspect is similar.
Our eyes appear to use a function called convolution to create the images we perceive as they pass from the retina to the brain. Some ANNsA type of neural network that’s loosely inspired by biological neurons, but operates very differently. specifically make use of convolution. Those networks are called convolutional neural networksA type of artificial neural network specifically used for machine-vision applications., or CNNs. They are the most common network in use, at least in applications that we can see. (Social media giants use lots of networks, but we don’t always get to see them).
The first thing here is the fact that different networks are good for different things. As common as CNNs are, to my knowledge, we use them only for machine visionTechnology that gives machines the ability to see things and make decisions based on what they see. (or applications that behave like that) – not for any other application. We’ll look at the structure of a CNN first, and then we’ll discuss other types of networks briefly.
CNNs – Convolution, Activation, and Pooling
A CNN can have many layers, but those layers can have different functions. First there is the mathematical notion of convolution; we’ll look at that more next week. But are two other aspects to these and other networks that bear some attention.
The first is the so-called activation function, and we’re also going to look more at that in a future post. In short, an activation function helps suppress inconsequential data, focusing us instead on the important stuff. So, after each convolution layer, the results are sent through an activation function.
After activation, the images in a CNN are downsampled or subsampled using a pooling layer – that is, reduced in detail. The idea of a CNN is to be able to identify features in the image. Those features start out in very specific pixel locations. If we smear that out a little bit, then very slight changes to the image won’t change the result. Pooling has that effect, making results less sensitive to slight, irrelevant variations.
We do this by taking a group of pixels – often 2×2 – and replacing those pixels with something representative of what’s in them. That usually means either an average of the values in the four pixels, or the maximum value of the four. So four values get replaced by one value. If there are slight changes to the image, then those averages or maxima won’t change. The image below shows what’s called max pooling, where the maximum is used. For the four orange cells, the biggest number is 6, so, after pooling, those four cells get replaced by the one orange cell with 6 in it. And so forth for the other colors.
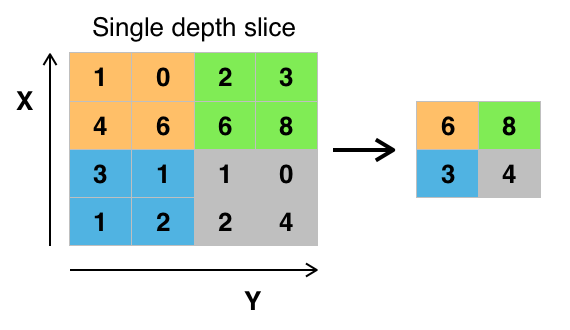
(Image credit: By Aphex34 – Own work, CC BY-SA 4.0)
Fully Connecting
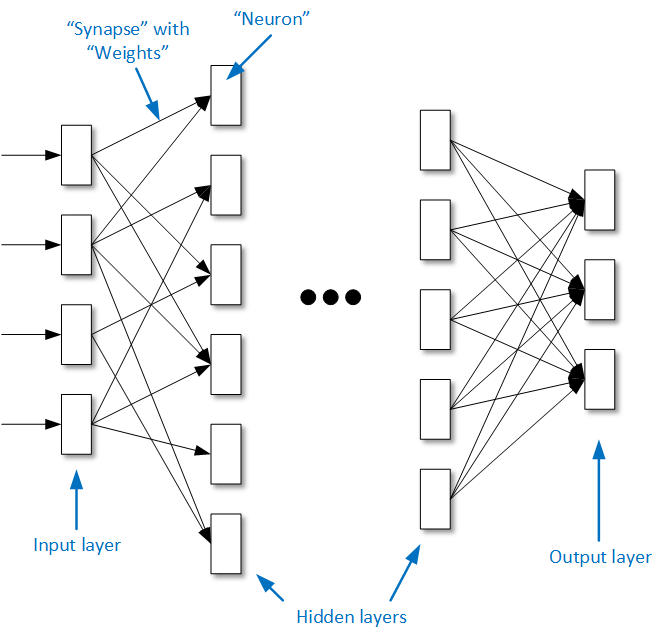
After pooling, there may be another convolution layer – and so forth until the last layer. In the last layer of a simple network, each “neuron” will represent, for instance, a classification – “dog,” “cat,” etc. And each one will contain some number that indicates a probability that the image contains that item. Very often, the last layer is fully connected. Most connections between layers are selective – each neuron gets its input from some, but not all, of the neurons in the prior layer. But in a fully connected layer, each layer gets input from all of the prior layer’s neurons.
In the following image (which we saw a couple weeks ago), you can see that, between the first layer and the first hidden layer, not all neurons connect to all neurons. But at the other end, we connect all the neurons in the next-to-last layer to every neuron in the last layer.
Other Neural-Network Configurations
CNNs aren’t the only networks out there, just like vision isn’t the only application. There’s another kind of network called a recurrent neural networkA type of artificial neural network used for analyzing streaming input like speech or handwriting., or RNN, that’s useful for speech and handwriting recognition. This is because of a critical difference between analyzing a picture (or video frame) and analyzing sound.
A picture is simply a two-dimensional array of pixels that are all available at one time. All processing happens on that image. But with things like speech, you’re analyzing a stream of information that comes over time. In other words, the decision you make on the bit of sound you’re hearing now will depend on what sound you already heard. So RNNs have little bits of memory in them to keep track of that. With CNNs, everything moves forward straight through. With RNNs, some of that data will stick around for use in figuring out the next sound to come in.
Networks and algorithmsA way of calculating something, typically as a step-by-step recipe. A familiar one to all of us is how we do long division on paper: that's an algorithm. Algorithms abound in the IoT. for processing them are under constant change, so in a year or two we could be having a very different conversation. Or maybe a similar but slightly different conversation. It’s a moving target.
Next week we dig into some convolutional math. While there are aspects of convolution that will feel… convoluted, it should be accessible.

Leave a Reply