

[From the last episode: We looked at trusted execution environmentsA separate area inside a processor where trusted software can run, with access to all resources. Software running outside that area has to access resources through the trusted area; it can’t do so directly.: portions of microcontrollers (MCUs) that have walled-off processorsA computer chip that does computing work for a computer. It may do general work (like in your home computer) or it may do specialized work (like some of the processors in your smartphone). for secureRefers to whether or not IoT devices or data are protected from unauthorized viewers. processing.]
We have one last topic before we review our tour through computing. We talked about cache as a way to speed up access to frequently-used data, and we looked at processing devices that have more than one processing coreThis can have more than one meaning. When discussing networks, the core is the heart of the network where much of the traffic (or at least that part that has to go a long ways to its destination) moves. This is in contrast to the edge -- the outer part of the network where devices like computers and printers get connected. When discussing computers, you can think of it as the same as a CPU. – so-called multicore devices. Well, how does cacheA place to park data coming from slow memory so that you can access it quickly. It's built with SRAM memory, but it's organized so that you can figure out which parts haven't been used in a while so that they can be replaced with new cached items. Also, if you make a change to cached data, that change has to make its way back into the original slow storage. play in such a systemThis is a very generic term for any collection of components that, all together, can do something. Systems can be built from subsystems. Examples are your cell phone; your computer; the radio in your car; anything that seems like a "whole."? After all, one core might be working from one part of memory while another works from another part, so, if they all share the same cache, they might be kicking each other’s stuff out.
On the other hand, there may be data that more than one core needs. If each core has its own independent cache, then there might be some wasted effort getting the same data twice for two different caches. And that’s just for reading data. What if one core changes some data, and that data is also in some other core’s cache? That second cache’s version of the data is now out of date, since the other core changed it.
Engineers address this problem using a tiered hierarchy of multiple caches along with the notion of cache coherence*. Let’s take those in turn.
Multiple Levels of Cache
The cache we were looking at before is referred to as a level-1 cache, or simply L1 cache. It’s right up close by the core for quick, easy access, and it’s usually split into separate sections for data and instructions. It’s optimized to be fast, but it’s not typically very large. In a multicoreDescribes a computer chip that has more than one CPU on it. system, each core normally gets its own L1 cache.
The next level of cache is usually bigger and a bitThe smallest unit of information. It is a shortened form of "binary digit." Since it's binary, it can have only two values -- typically 0 and 1. slower than L1 cache. Unsurprisingly, it’s called L2 cache. L2 cache may be shared between cores or dedicated to each core. Unlike L1 cache, however, it usually mixes data and instructions rather than separating them out.
The next level of cache above this – L3 cache – is most typically shared between cores. That means that data fetched for one core is also available to the other cores so they don’t have to do separate fetches. The other benefit of sharing the cache is that, if one core changes the value in the shared cache, then all the other cores have access to the new value.
There is even sometimes an L4 cache, although it’s less common. It’s also shared, and bigger than L3 (and also slower, but still faster than the original DRAMStands for "dynamic random access memory." This is temporary working memory in a computer. When the goes off, the memory contents are lost. It's not super fast, but it's very cheap, so there's lots of it.).
The challenge is that, when fetching new data from memory, it first goes into the highest-level cache (L3 or L4), and then, from there, moves into the lower levels. So it has to pass through them all to get to the L1 cache, where it is finally available for use.
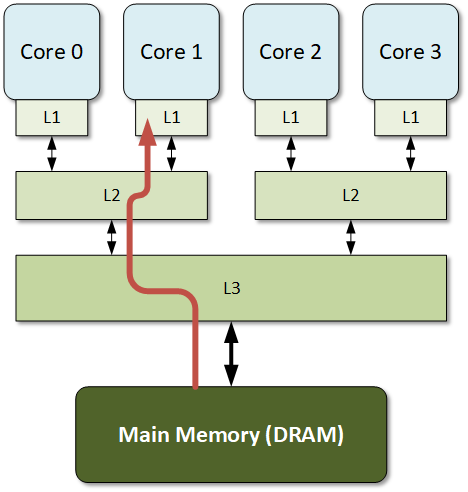
Figure 1. An example of three layers of cache. There are many options for doing this; this figure shows but one.
The arrow illustrates the path that data takes to get to Core 1.
Keeping Coherent
Now let’s take on the other challenge: when one core changes data. We’ve seen that any core attacked to a shared cache can use data once updated in that shared cache, but cores don’t work directly from the shared caches: they work from their own L1 caches. In some cases, nothing else is necessary. Let’s say, for example, that Core 1 needed some data and brought it all the way into its L1 cache. Core 1 then changes the data, so its version in the shared L2 or L3 cache is updated. If Core 2 now wants to use the data, it brings the new value into its L1 cache to use, and everything is fine.
But what if Core 2 pulls the value in before Core 1 changes it? Now Core 2 has a stale version of the data. The term used to describe this stateA broad term that can apply to a lot of systems. Let’s say you have a system that can be one of two ways – on or off. That “on-ness” or “off-ness” is the state of the system. The system is either in an on state or an off state. Many different kinds of systems can have many different kinds of state. There are many complex branches of engineering or physics or even mathematics that deal with state. The easiest way to think of any of them is, “the way things are” (which may depend on the history of prior states, meaning how they got to this particular state). of the system is coherence. If all of the versions of a specific piece of data agree in all the L1 caches that contain it, then it’s coherent. If not, it’s incoherent. Clearly, if one core changes data that’s in multiple cores’ L1 caches, then the system becomes incoherent if we do nothing else.
Cache coherence is a big topic on its own. There are many approaches, but they all have some way of noticing that data changed in one place and then updating the other locations where that data exists. This isn’t a trivial thing to do – after all, if you decide you need to update a specific L1 cache right when that core uses the stale version of the data because you weren’t able to update it quickly enough, then you’ve got a problem. We’re not going to get into those details, but suffice it to say that an astonishing amount of work has gone into figuring out how to keep caches coherent.
This little video illustrates how cache coherence works at a very basic level.
*You’ll often see “coherency” in place of “coherence.” For our purposes, they mean the same thing.

Leave a Reply