

[From the last episode: We looked at what it means to do machine learningMachine learning (or ML) is a process by which machines can be trained to perform tasks that required humans before. It's based on analysis of lots of data, and it might affect how some IoT devices work. “at the edgeThis term is slightly confusing because, in different contexts, in means slightly different things. In general, when talking about networks, it refers to that part of the network where devices (computers, printers, etc.) are connected. That's in contrast to the core, which is the middle of the network where lots of traffic gets moved around.,” and some of the compromises that must be made.]
When doing ML at the edge, we want two things: less computing (for speed and, especially, for energy) and smaller hardwareIn this context, "hardware" refers to functions in an IoT device that are built into a silicon chip or some other dedicated component. It's distinct from "software," which refers to instructions running on a processor. that requires less memory. We saw that “rounding” from real numbers to integers is one way to do that. In fact, you can even select how precise you want those integers to be. Less precision means less memory and computing, but also less accuracy. Does accuracy drop too far? Designers have to test to see, and perhaps make compromises.
But there are other things that designers can do to take the original models and make them smaller. All of them will have some impact on accuracy, so they have to be done carefully, with an eye towards not hurting accuracy too much. We’ll talk about two specific optimization techniques, one called pruning and one called layer fusion.
Tiny numbers
We saw how sparsity can help reduce the amount of calculation. That happens when a weight or activation is zero: why bother multiplying and adding, when you know the answer already? But that’s only if the weight is already zero. But what if it’s not zero, but just really, really small?
Let’s say that most of the weights are in the 5, 10, -2, -7 range (just making numbers up). And then you have a weight that’s 0.109. That’s not zero, so it’s technically not sparse. But, then again, with all of those other numbers being so much bigger – 20 times as big, at least – the calculation using that tiny number of hardly going to make a difference.
If it’s hardly going to make a difference, then why bother? Just call it zero and then – bingo – sparsity. This is what happens when pruning a model. Why is it called pruning? Because you’re really doing more than just setting a number to zero. If a connection from one layer to the next has a weight of zero, then you might as well remove the connection, since, once it’s zero, it has no effect.
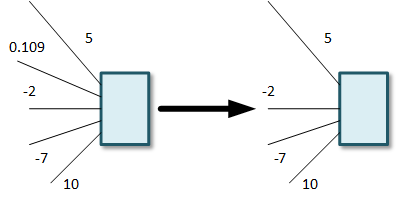
You can do this across the whole model – find super-small weights and remove those connections, just like removing branches from a tree. Hence “pruning.” You now end up with a smaller model – meaning it has fewer connections – and it will now be easier to calculate.
Setting Up for Calculating
Layer fusion is a little different. Exactly how a neural networkA type of conceptual network organized in a manner inspired by our evolving understanding of how the brain works. is calculated will depend on the kind of hardware you’re using to do the calculations. There are new architectures coming out that have lots of computing elements all over the place that can operate at the same time. With something like that, you might be able to calculate an entire layer at once. In that case, you’d likely move through the network, calculating one layer at a time, until you’re done.
But older architectures may just use CPUs. Technically, you could have one CPUStands for "central processing unit." Basically, it's a microprocessor - the main one in the computer. Things get a bit more complicated because, these days, there may be more than one microprocessor. But you can safely think of all of them together as the CPU. that has to do everything. In that case, you’d take one node on one layer, calculating one weight at a time to finish the node, and then move to the next node. Keep doing that to finish one layer and then start over with the next layer. Kind of like a typewriter. (Remember those?)
There’s a certain amount of work that’s needed to calculate a node. Most importantly, you need to go get the weights so that you know what numbers you’re working with. For each node, you have to get the weights, since they’re likely all different from node to node (and certainly from layer to layer). How many weights you need to get depends on how much calculation you’re doing at once. If you’re doing one node, then you need that node’s weights. If you’re doing a whole layer, then you need all of the weights for that layer.
2 into 1
Here’s the thing: it takes time and – especially – energy to get those weights. And when you’re done with one node, you need to store the results to make room for the next calculation – especially if you’re doing one node at a time. So when you start the next layer, not only do you need to get more weights, but you also need to get the results from the prior layer.
All that memory fetching is a big problem, and designers are coming up with all kinds of creative ways to improve the situation. That’s not the main point right now, however. The point for the moment is that each layer involves some overhead before you can do the work.
So… what if two adjacent layers had relatively simple calculations and you could do them both at once? In this case, you could squash the layers together to make them look like one layer and combine the calculations. How easy that would be would depend on the specific math – in particular, the activation functions being used.
But let’s assume you can do that. What you’ve just done is to fuse those two layers into a single layer. Now you can be more efficient with the fetching. To be clear, this isn’t something that happens while you’re actually doing inferenceFor machine learning, this refers to the process of making decisions using a model. Before the decisions can be made accurately, training must occur.. It’s not like you’re in the middle of the task and you say, “Hmmm, I just noticed that I can combine things!” No, this is something you do to the model while developing it. When the model is then used in real life, the layers are already fused (and the hardware won’t even know that they were originally two layers instead of one).
We’re going to take on one more ML concept, but we’re going to need to do some background work first. That will happen over the next couple of weeks.

Leave a Reply